正则表达式(1)
主题
正则表达式(1)
通过正则表达式提升工作效率
场景1,检查发现大量的 System.out.println
我们可以通过正则表达式,批量替换
打开
IDE(IDEAorEclipse)或编辑器(VSCodeorUE),选择文件间批量替换(类似意思,目的是检索所有文件)这里以
VSCode为例,我准备了11个一模一样的文件:public class A {
public void m1(String x){
System.out.println("hello," + x);
}
public void m2(String x){
System.out.println("goodbye," + x);
}
public void m3(String x){
System.out.println("balabalah..." + x);
}
}只是演示,所以命名并不遵守
Java要求:➜ xyz ls -al
total 44
drwxr-xr-x 2 helly helly 260 Mar 30 12:48 .
drwxrwxrwt 31 root root 1220 Mar 30 12:49 ..
-rw-r--r-- 1 helly helly 262 Mar 30 12:41 A10.java
...
-rw-r--r-- 1 helly helly 262 Mar 30 12:41 A9.java输入正则表达式
System.out.println\("(.*)" \+ (.*)\);$作为查询值,输入LOGGER.info("$1{}",$2);作为替换值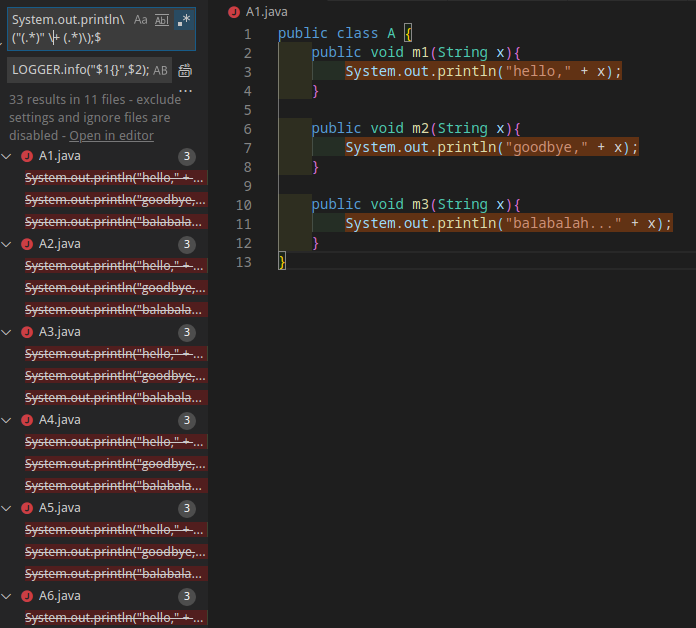
点击替换,结果如下:

重点
解读正则表达式 System.out.println\("(.*)" \+ (.*)\);$ 和替换值 LOGGER.info("$1{}",$2);
Q:
(.*)什么意思?A:表明这是一个捕获组,捕获的结果将存入匹配组中。这里的输入中有两个捕获组,第一个捕获组目标是西文引号内内容,第二个捕获组目标是变量。
Q:
$1和$2什么意思?A:表明在替换中引用刚才捕获组中的信息。默认地,全匹配时的组号是0,然后第一个捕获组是1,以此类推。
通过正则表达式,我们可以快速将这类规范的数据转换为我们想要的形式。
场景2,查找关键日志
一个日志很大,达到
以一份 IBM JDK 的 GC 日志为例,非常大,阅读困难。
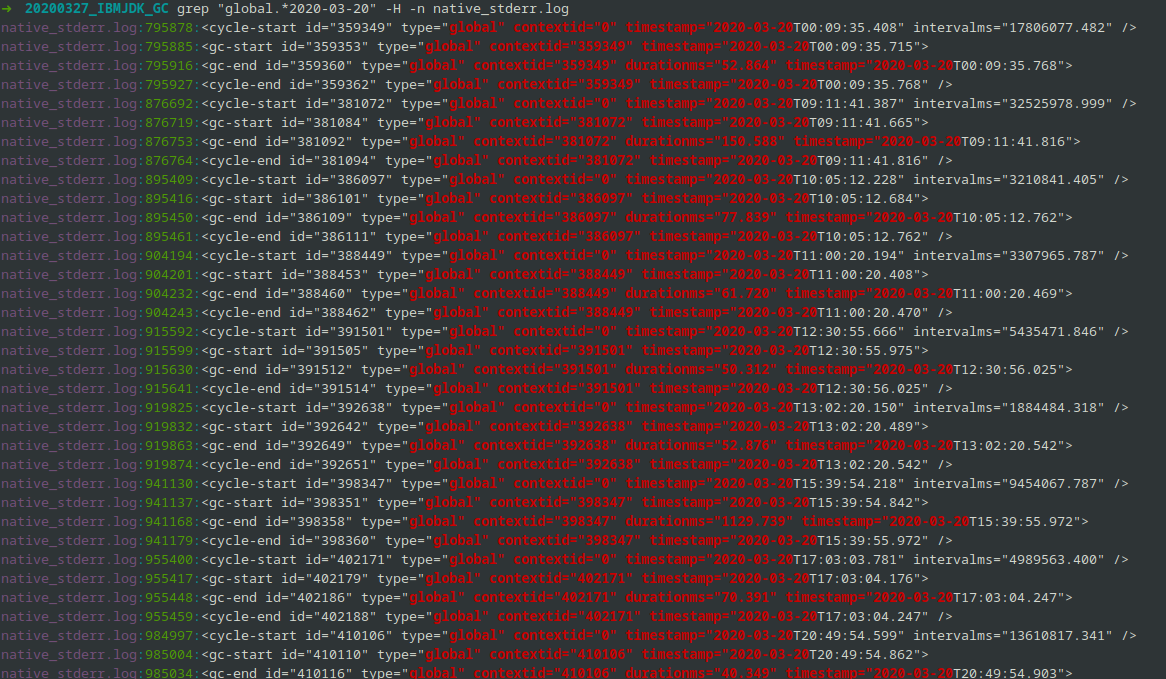
假设我们只关心3月20日的 Full GC,也就是关键字 global,我们可以这样:
➜ 20200327_IBMJDK_GC grep "global.*2020-03-20" -H -n native_stderr.log |
重点
找到关键字,然后基于关键字过滤日志,得到尽可能短的有效日志仔细分析。
关键字可以是线程名(用来分析单线程执行情况),可以是用户信息(用来分析用户信息),也可以是时间点(基于时间信息进行交叉分析)。聚焦正确的话,分析可以做到又快又准。
场景3,基于日志进行统计
通过编写日志统计脚本,可以快速统计一些重要信息,比如响应耗时、TPS等等。而这种统计的基石,就是正则表达式。在没有日志工具或平台支持的情况下,通过简单编写 Python 脚本,就能做到。
lineRegexList = [ |
通过匹配正则表达式,我们可以统计日志,得到执行结果(数据非真实,已处理):
20200312 |
小结
正则表达式是程序员的语言,是程序员提升工作效率的神器。配合优秀的工具,再加上正则表达式的助威,效率提升会十分明显。